반응형
용두사미
ㅁ The MINIST Dataset of Handwirtten numbers

파일을 아나콘다에서 실행해서 폴더를 만들고 거기에 데이터를 업로드를 한다.
그리고 파일을 해당 폴더가 있는 폴더에서 notebook을 실행하고 아래의 내용을 실행하면 100이 나온다.
출력값의 범위는 활성함수의 출력 범위에 있어야한다.
로지스틱 함수의 범위 => 0.0 ~ 1.0(실제론 양 끝단에 도달할 수없다.
결과값은 출력이 어떻게되어야하는가?
이미지로출력? 28 x 28 = 784개의 출력노드 필요한것인가?
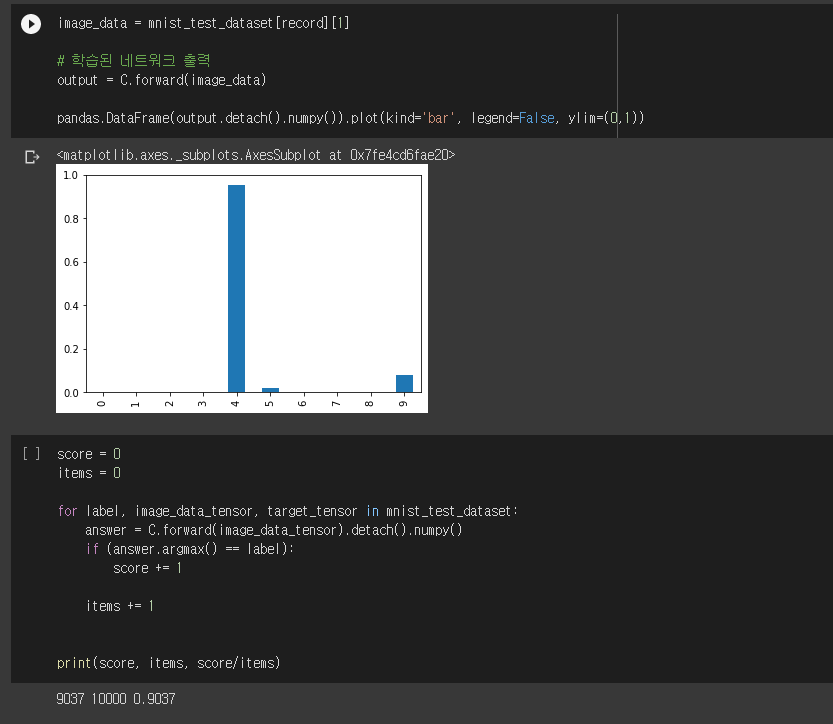
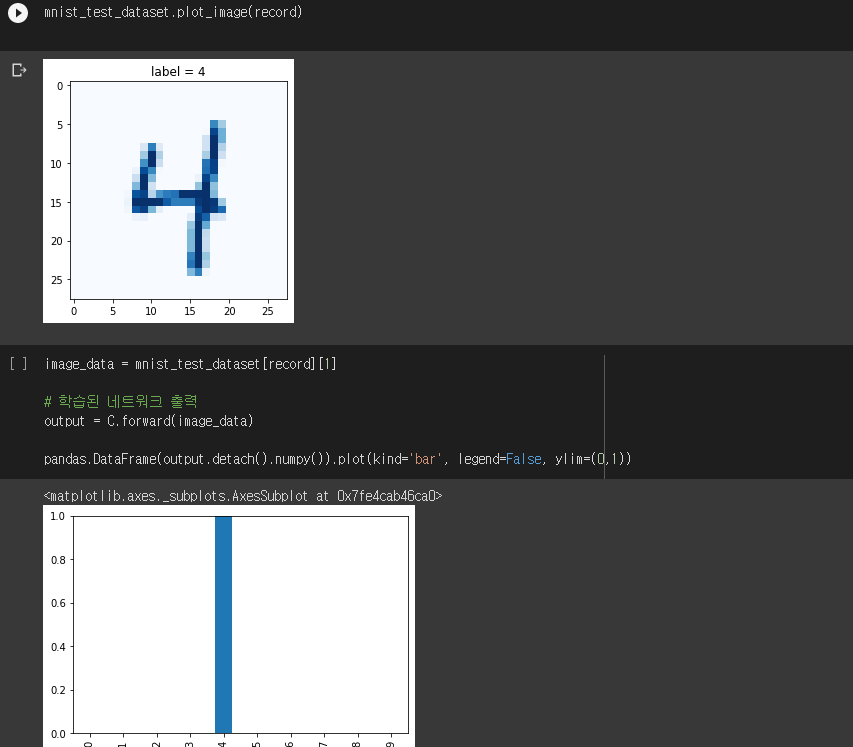
이미지를 분류해 정확한 클래스에 할당하는 것이 목표다.
0 ~ 9 까지 총 10개의 출력 노드에 각각 결과 값 할당
https://colab.research.google.com
Google Colaboratory
colab.research.google.com
여기서 손쉽게 테스트해볼 수 있다.
구글드라이브랑 연결하여 데이터를 삽입한다.
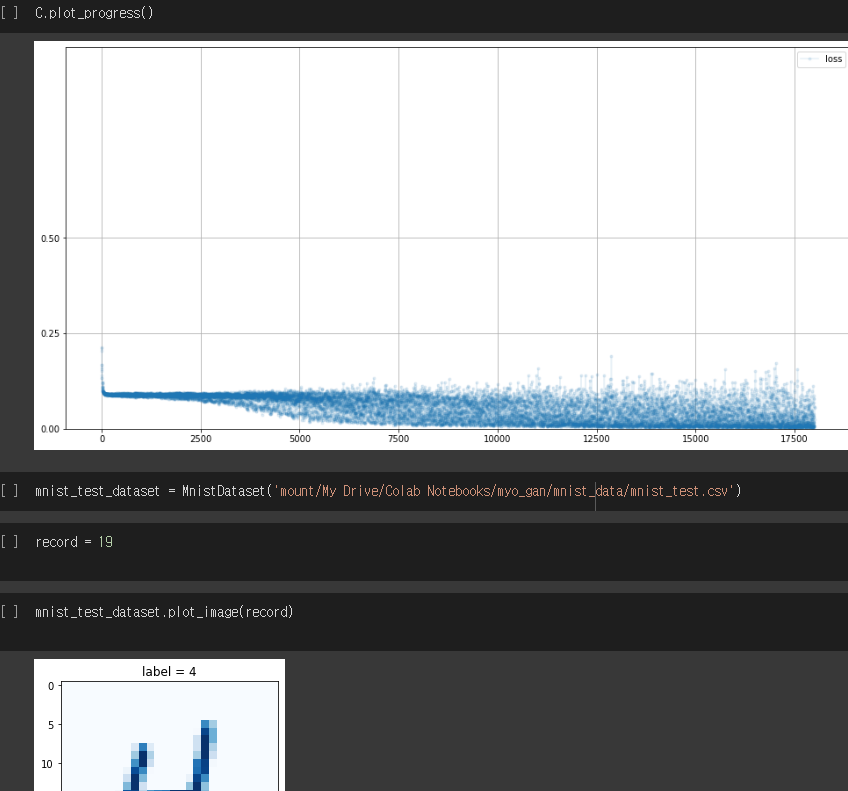
class Classifier(nn.Module): def __init__(self): # initialise parent pytorch class super().__init__() # 신경망 정의 self.model = nn.Sequential( nn.Linear(784, 200), nn.Sigmoid(), nn.Linear(200, 10), nn.Sigmoid() ) # 오차함수 self.loss_function = nn.MSELoss() # 가중치 업데이트 self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01) # counter and accumulator for progress self.counter = 0 self.progress = [] def forward(self, inputs): # 모델 실행 return self.model(inputs) def train(self, inputs, targets): # 모델 출력 계산 outputs = self.forward(inputs) # 오차 계산 loss = self.loss_function(outputs, targets) # increase counter and accumulate error every 10 self.counter += 1 if (self.counter % 10 == 0): self.progress.append(loss.item()) if (self.counter % 10000 == 0): print("counter = ", self.counter) # zero gradients, perform a backward pass, and update the weights self.optimiser.zero_grad() loss.backward() self.optimiser.step() #오차값 그래프 표현 def plot_progress(self): df = pandas.DataFrame(self.progress, columns=['loss']) df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
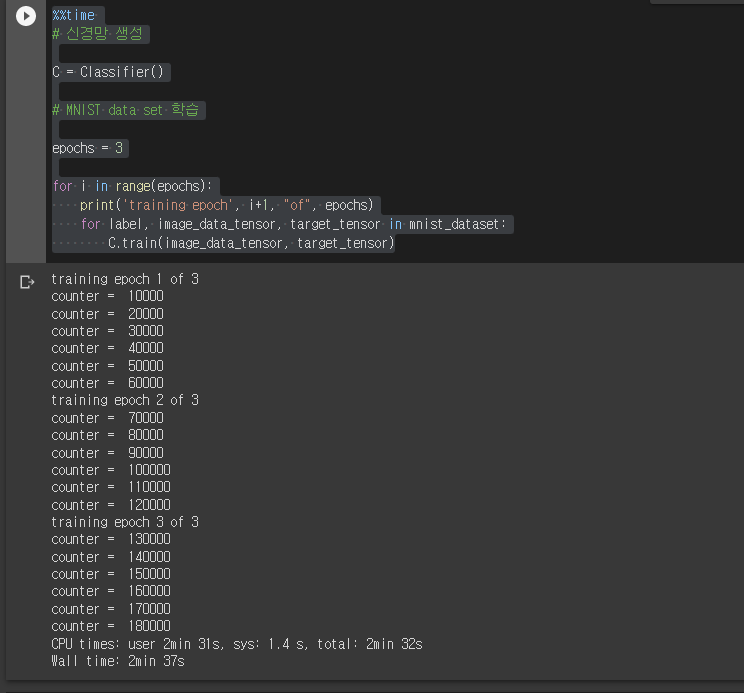
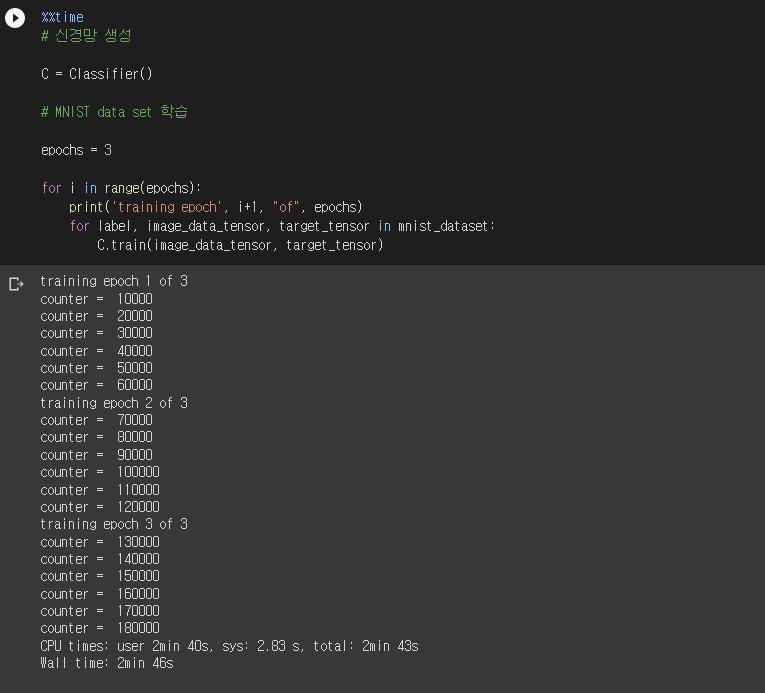
%%time # 신경망 생성 C = Classifier() # MNIST data set 학습 epochs = 3 for i in range(epochs): print('training epoch', i+1, "of", epochs) for label, image_data_tensor, target_tensor in mnist_dataset: C.train(image_data_tensor, target_tensor)

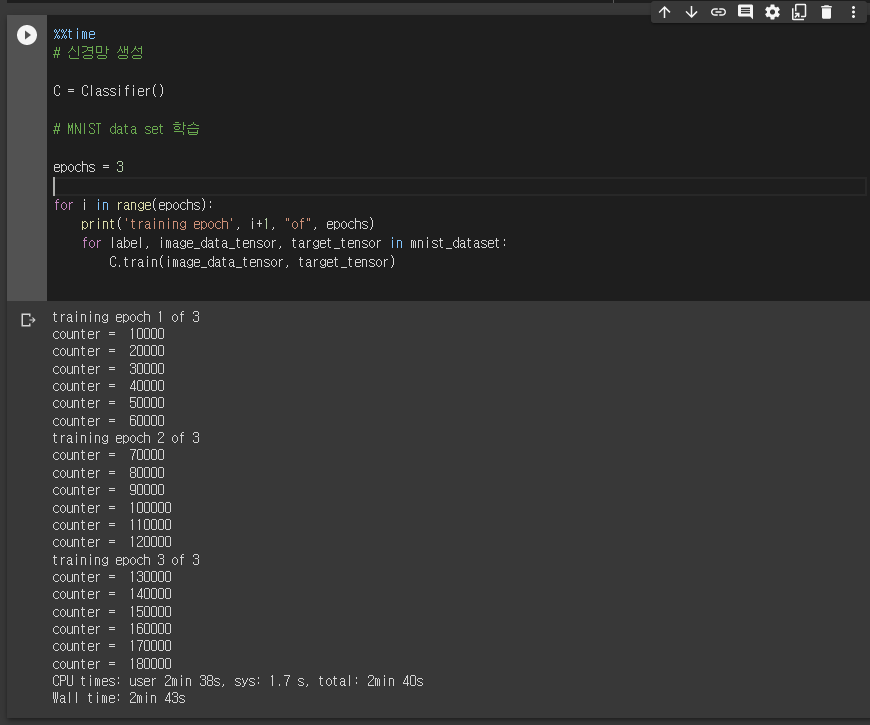
class Classifier(nn.Module): def __init__(self): # initialise parent pytorch class super().__init__() # 신경망 정의 self.model = nn.Sequential( nn.Linear(784, 200), nn.Sigmoid(), nn.Linear(200, 10), nn.Sigmoid() ) # 오차함수 #self.loss_function = nn.MSELoss() self.loss_function = nn.BCELoss() # 가중치 업데이트 self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01) # counter and accumulator for progress self.counter = 0 self.progress = [] def forward(self, inputs): # 모델 실행 return self.model(inputs) def train(self, inputs, targets): # 모델 출력 계산 outputs = self.forward(inputs) # 오차 계산 loss = self.loss_function(outputs, targets) # increase counter and accumulate error every 10 self.counter += 1 if (self.counter % 10 == 0): self.progress.append(loss.item()) if (self.counter % 10000 == 0): print("counter = ", self.counter) # zero gradients, perform a backward pass, and update the weights self.optimiser.zero_grad() loss.backward() self.optimiser.step() #오차값 그래프 표현 def plot_progress(self): df = pandas.DataFrame(self.progress, columns=['loss']) df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
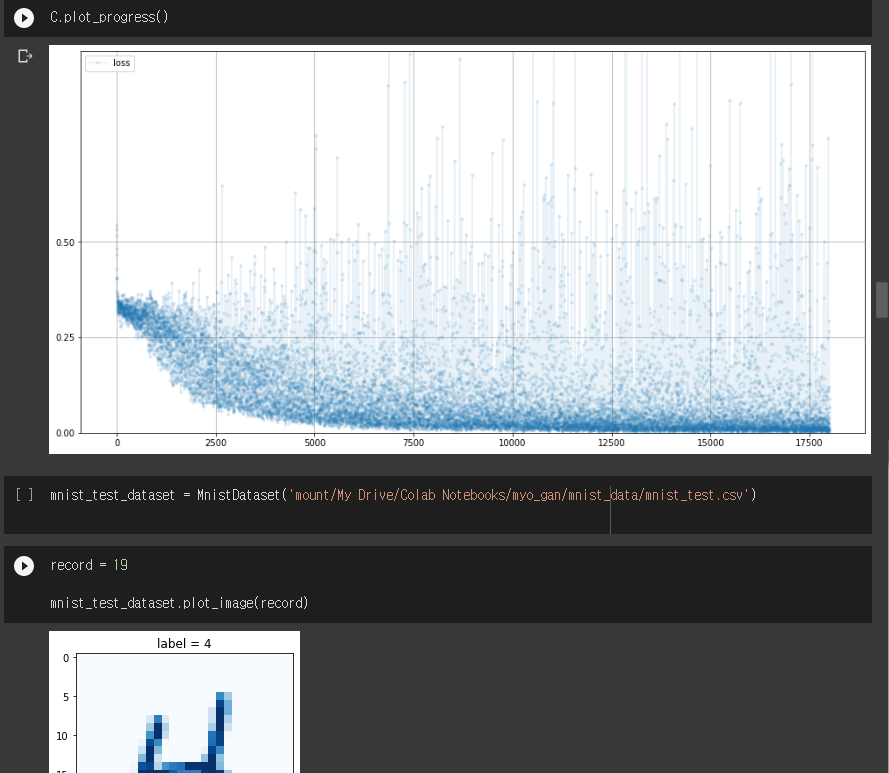
class Classifier(nn.Module): def __init__(self): # initialise parent pytorch class super().__init__() # 신경망 정의 self.model = nn.Sequential( nn.Linear(784, 200), #nn.Sigmoid(), nn.LeakyReLU(0.02), nn.Linear(200, 10), nn.LeakyReLU(0.02) #nn.Sigmoid() ) # 오차함수 self.loss_function = nn.MSELoss() #self.loss_function = nn.BCELoss() # 가중치 업데이트 self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01) # counter and accumulator for progress self.counter = 0 self.progress = [] def forward(self, inputs): # 모델 실행 return self.model(inputs) def train(self, inputs, targets): # 모델 출력 계산 outputs = self.forward(inputs) # 오차 계산 loss = self.loss_function(outputs, targets) # increase counter and accumulate error every 10 self.counter += 1 if (self.counter % 10 == 0): self.progress.append(loss.item()) if (self.counter % 10000 == 0): print("counter = ", self.counter) # zero gradients, perform a backward pass, and update the weights self.optimiser.zero_grad() loss.backward() self.optimiser.step() #오차값 그래프 표현 def plot_progress(self): df = pandas.DataFrame(self.progress, columns=['loss']) df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))

import numpy # scipy.special for the sigmoid function expit() import scipy.special # library for plotting arrays import matplotlib.pyplot # ensure the plots are inside this notebook, not an external window %matplotlib inline # neural network class definition class NeuralNetwork: # initialise the neural network def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate): # set number of nodes in each input, hidden, output layer self.inodes = inputnodes self.hnodes = hiddennodes self.onodes = outputnodes # link weight matrices, wih and who # weights inside the arrays are w_i_j, where link is from node i to node j in the next layer # w11 w21 # w12 w22 etc self.wih = numpy.random.normal(0.0, pow(self.inodes, -0.5), (self.hnodes, self.inodes)) self.who = numpy.random.normal(0.0, pow(self.hnodes, -0.5), (self.onodes, self.hnodes)) # learning rate self.lr = learningrate # activation function is the sigmoid function self.activation_function = lambda x: scipy.special.expit(x) # train the neural network def train(self, inputs_list, targets_list): # convert inputs list to 2d array inputs = numpy.array(inputs_list, ndmin=2).T targets = numpy.array(targets_list, ndmin=2).T # calculate signals into hidden layer hidden_inputs = numpy.dot(self.wih, inputs) # calculate the signals emerging from hidden layer hidden_outputs = self.activation_function(hidden_inputs) # calculate signals into final output layer final_inputs = numpy.dot(self.who, hidden_outputs) # calculate the signals emerging from final output layer final_outputs = self.activation_function(final_inputs) # output layer error is the (target - actual) output_errors = targets - final_outputs # hidden layer error is the output_errors, split by weights, recombined at hidden nodes hidden_errors = numpy.dot(self.who.T, output_errors) # update the weights for the links between the hidden and output layers self.who += self.lr * numpy.dot((output_errors * final_outputs * (1.0 - final_outputs)), numpy.transpose(hidden_outputs)) # update the weights for the links between the input and hidden layers self.wih += self.lr * numpy.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)), numpy.transpose(inputs)) # query the neural network def query(self, inputs_list): # convert inputs list to 2d array inputs = numpy.array(inputs_list, ndmin=2).T # calculate signals into hidden layer hidden_inputs = numpy.dot(self.wih, inputs) # calculate the signals emerging from hidden layer hidden_outputs = self.activation_function(hidden_inputs) # calculate signals into final output layer final_inputs = numpy.dot(self.who, hidden_outputs) # calculate the signals emerging from final output layer final_outputs = self.activation_function(final_inputs) return final_outputs # number of input, hidden and output nodes input_nodes = 784 hidden_nodes = 100 output_nodes = 10 # learning rate learning_rate = 0.2 # create instance of neural network n = NeuralNetwork(input_nodes,hidden_nodes,output_nodes, learning_rate) # load the mnist training data CSV file into a list training_data_file = open("mnist_dataset/mnist_train.csv", 'r') training_data_list = training_data_file.readlines() training_data_file.close() # train the neural network # epochs is the number of times the training data set is used for training epochs = 7 for e in range(epochs): # go through all records in the training data set for record in training_data_list: # split the record by the ',' commas all_values = record.split(',') # scale and shift the inputs inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01 # create the target output values (all 0.01, except the desired label which is 0.99) targets = numpy.zeros(output_nodes) + 0.01 # all_values[0] is the target label for this record targets[int(all_values[0])] = 0.99 n.train(inputs, targets) # load the mnist test data CSV file into a list test_data_file = open("mnist_dataset/mnist_test.csv", 'r') test_data_list = test_data_file.readlines() test_data_file.close() # test the neural network # scorecard for how well the network performs, initially empty scorecard = [] # go through all the records in the test data set for record in test_data_list: # split the record by the ',' commas all_values = record.split(',') # correct answer is first value correct_label = int(all_values[0]) # scale and shift the inputs inputs = (numpy.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01 # query the network outputs = n.query(inputs) # the index of the highest value corresponds to the label label = numpy.argmax(outputs) # append correct or incorrect to list if (label == correct_label): # network's answer matches correct answer, add 1 to scorecard scorecard.append(1) else: # network's answer doesn't match correct answer, add 0 to scorecard scorecard.append(0) # calculate the performance score, the fraction of correct answers scorecard_array = numpy.asarray(scorecard) print ("performance = ", scorecard_array.sum() / scorecard_array.size)
반응형
'Develop > AI' 카테고리의 다른 글
| 인공지능(신경망, 딥러닝) 교육 정리(Artificial Neural Network 3) (0) | 2023.01.15 |
|---|---|
| 인공지능(신경망, 딥러닝) 교육 정리 (Preparing Data) (0) | 2023.01.08 |
| 인공지능(신경망, 딥러닝) 교육 정리(Artificial Neural Network 2) (0) | 2023.01.08 |
| 인공지능(신경망, 딥러닝) 교육 정리 (Backpropagation) (0) | 2023.01.08 |
| 인공지능(신경망, 딥러닝) 교육 정리(Artificial Neural Network 1) (0) | 2023.01.08 |





최근댓글